
I have long been a fan of R-bloggers, a content aggregating site focused on blog posts about R. It serves a useful purpose1 and has considerable reach.2 But in the first version of this blog post, I actually wrote a lengthy critique of the site where I concluded with a not-so-blunt suggestion that R-bloggers wasn’t as good as it should be. In retrospect, and after pleasant exchange about a draft of the post with Tal Galili (the creator and operator of R-bloggers), I can confidently say my post was overly nit-picky and unrealistic in my expectations for a benevolent blog-aggregating site like R-bloggers.
Background on R-bloggers
As I already mentioned, R-bloggers is an R-related content aggregating site that circulates and indexes blog posts about R. It was created, as far as I can tell, in 2005 by Tal Galili, who is, impressively, still listed as the sole maintainer of the site–though it also appears to be affiliated with the Foundation for Open Access Statistics (FOAS), so, hopefully, they provide Tal with some support.
As for its mission and a description of its basic operations, here’s the explanation straight from R-bloggers’ about section:
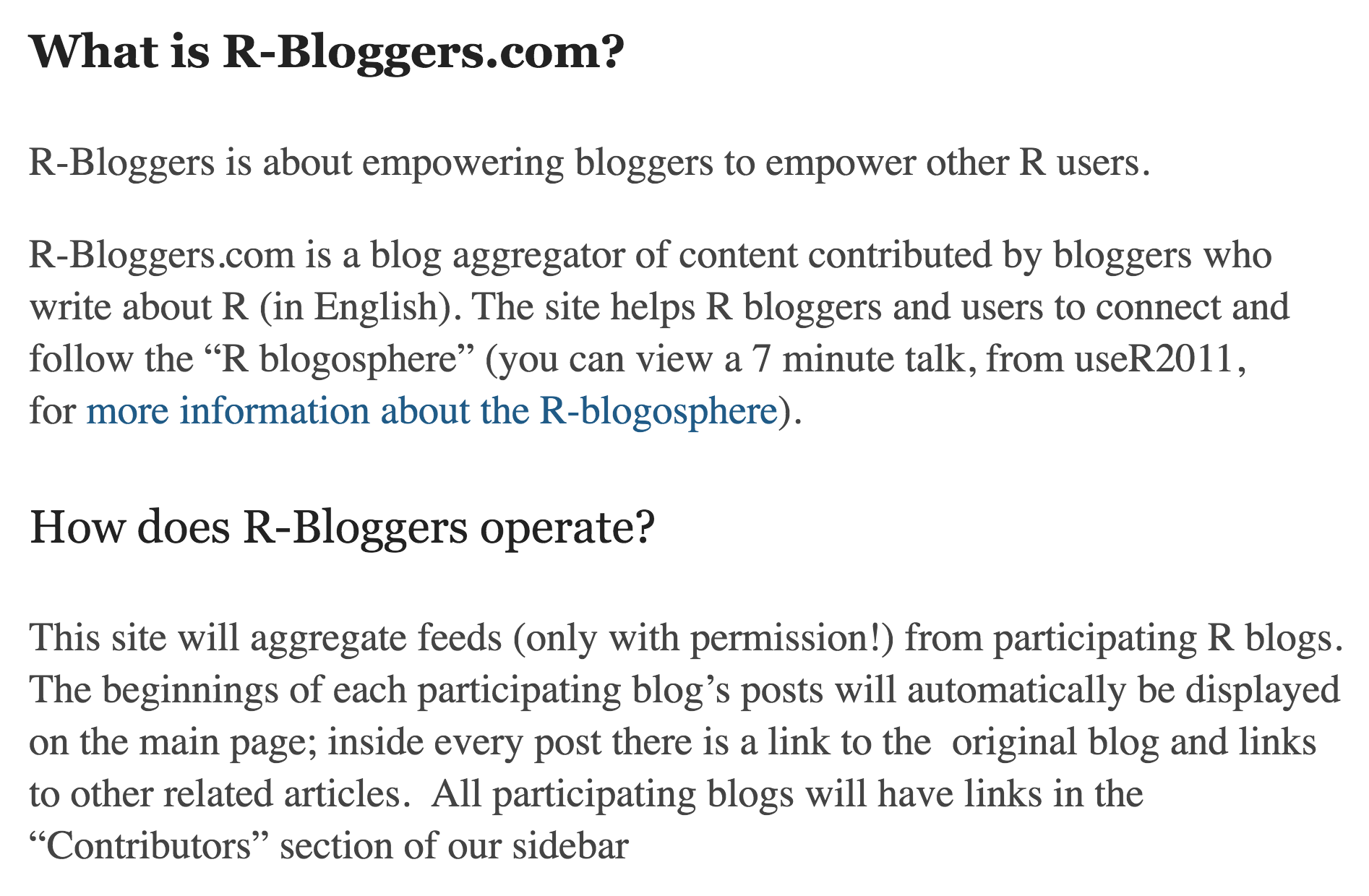
And here’s the explanation of what R-bloggers offers to bloggers:

Anyone interested in adding their blog to the R-bloggers feed is also provided with a link containing instructions and a submission form for adding a blog to R-bloggers. The guidelines for bloggers are quite reasonable–blog posts should be about R, include a minimum amount of well-written non-code content (i.e., code snippets are not discouraged, but they should be accompanied by text), contain reasonably reproducible examples/use cases (if relevant), compatible HTML code, and a link back to R-bloggers, etc.
R-bloggers’ contribution to #rstats
Ultimately, the contribution made by R-bloggers is not necessarily the production of content, but the dissemination it. When one considers some of the difficulties associated with running or automating this kind of service, it’s easy to understand why the dissemination of R-related content is a valuable contribution. But it’s perhaps even easier to understand the value of its contribution by actually trying to automate the process yourself…
So, in addition to qualifying as my R-bloggers link, the goal of this post is to create via automation a content-aggregating R-bloggers-like website.
Identifying blogs
Without scraping the R-bloggers website, I was able to accumulate a large list of R-related blogs by searching
for tweets via rtweet containing R-related keywords and URLs that matched at
least one of two common blog post conventions (/post/ or 2018/\\d{2}/).
## build search query with URL filters
m <- substr(Sys.Date(), 6, 7)
sq <- glue::glue(
'(rstats OR tidyverse OR "R package") (url:post OR url:2018/{m})')
## search for most recent 100 matching tweets
rt <- rtweet::search_tweets(sq, n = 100)
## print URLs
rt %>%
pull(urls_expanded_url) %>%
unlist() %>%
tfse::na_omit() %>%
unique()
#> [1] "https://figshare.com/articles/RCCPII_Data/7928480"
#> [2] "http://thug-r.life/post/2019-04-03-tale-of-three-assignment-operators/"
#> [3] "https://buff.ly/2UHhohr"
#> [4] "http://bit.ly/learning-lab-07"
#> [5] "http://bit.ly/lstm-time-series"
#> [6] "https://tenet-rccpii.github.io/rccpii-2018/"
#> [7] "https://carpentries.org/blog/2019/04/rccpii/"
#> [8] "https://nemethc.com/post/2019-04-05-seattle-bike-trafic/"Automating a website
Then, after using rvest to extract post information and text previews from RSS
feeds, I was able to automate, with the help of blogdown, a continuously
updating website with a feed containing linked post previews. It took a good amount of elbow grease, but, at least
initially, the task seemed surprisingly doable. I was so confident in my ability to automate an R-bloggers-like
website, I even decided to expand the aim of my content aggregating feed to be about data-science generally–hence,
the name, data-scribers. You can see the site for yourself at data-scribers.mikewk.com.
No match for R-bloggers
While the initial outcome appeared to be a resounding success, it wasn’t long before I realized the difficulties involved in pruning (e.g., cutting off text, including/not including code chunks, dealing with inconsistent formats, etc.), filtering (e.g., on-topic, non-trivial, consistent language, original content, non-reposts, etc.), and maintaining (checking/updating/editing algorithm, tagging posts, creating searchable and/or organized archive, etc.) a site like R-bloggers would be a lot of work. In fact, since launching data-scribers, the site has started to take on a life of its own; the range of topics and languages keep growing, and, at this point, I’m more interested to see where it goes than I am in investing additional time ensuring the feed only contains English posts, filtering via some overly-strict definition of data-science, battling with HTML formatting issues, etc.
Of course, even if I had time to prune, filter, and maintain the feed of post previews, to truly be competitive with R-bloggers, I’d also have to add numerous other features (visuals, linked tags, search bar, etc.)–and even then the site wouldn’t include any integration with R-related advertisement opportunities or job postings.
Notes
1 R-bloggers is a centralized directory of “over 750” R-related blogs
2 At the time of writing, the site has 50k email subscribers, 60k+ Twitter followers, etc.